install.packages("pacman") #para instalar
library(pacman) # para llamar/cargarPráctica 4. Análisis descriptivo de datos en R
Sesión del jueves, 11 de mayo de 2023
Presentación
Objetivo de la práctica
El objetivo de esta guía práctica es conocer las principales formas de realizar analísis estadísticos descriptivo en R, aplicando los concocimientos aprendidos durante el curso.
En detalle, aprenderemos:
Establecer un flujo de trabajo ordenado en un script (.R).
Aplicar análisis estadísticos descriptivos a variables según su nivel de medición
Recursos de la práctica
En esta práctica trabajeremos con los datos procesados que obtuvimos en la práctica anterior a partir de los datos del Estudio Longitudinal Social de Chile (ELSOC) realizado por COES.
Recuerden que siempre es importante trabajar con el manual/libro de códigos de las bases de datos. El manual de la ELSOC 2022 lo pueden encontrar aquí.
Flujo de trabajo reproducible
Por temas de orden y reproducibilidad, en este curso vamos a separar en dos momentos el trabajo con datos, y dos archivos de código correspondientes:
Preparación: corresponde a lo que se conoce generalmente como “limpieza”, es decir, realizar las modificaciones necesarias a los datos para poder efectuar los análisis. Estas modificaciones previas al análisis son necesarias ya que los datos originales con los que se va a trabajar en general no vienen perfectamente adaptados a los análisis que se quieren hacer. Por lo tanto, en cuanto a datos también hacemos la distinción entre datos originales y datos preparados (o procesados).
Análisis: se relaciona con análisis estadísticos, en este caso descriptivos, asociados a las preguntas e hipótesis de investigación.
Los procesos de preparación y análisis vinculados tanto a datos y resultados se presentan en el siguiente esquema:
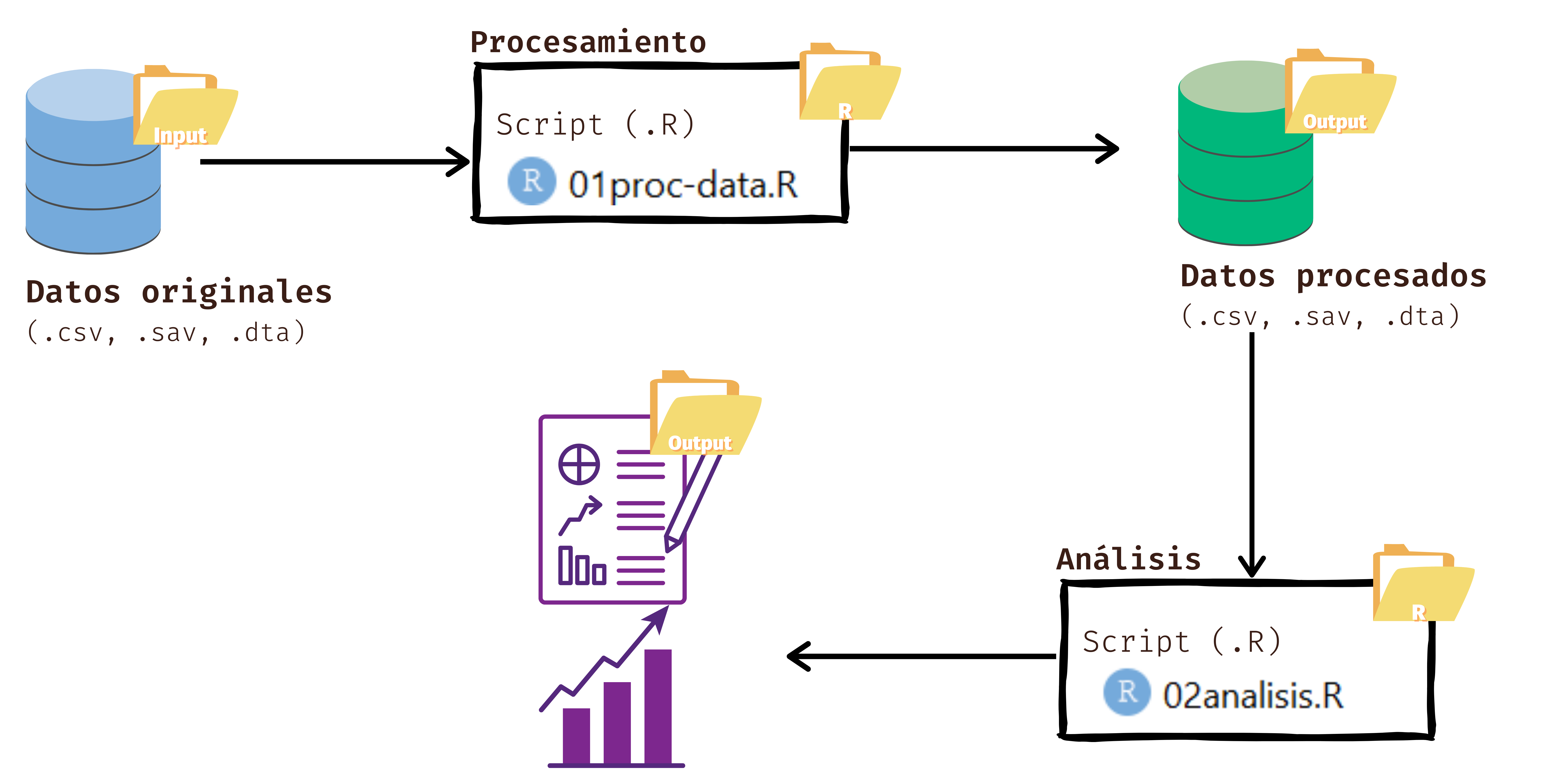
Tanto la preparación como el análisis (que son parte del concepto más general de procesamiento) quedan registrados cada uno en un archivo de código respectivo.
En esta guía nos centraremos en el análisis de datos con R. El documento de código de análisis tiene, por lo menos, 4 partes más una sección de identificación inicial:
- Identificación y descripción general: Título, autor(es), fecha, información breve sobre el contenido del documento
- Librerías: instalar/cargar librerías a utilizar
- Datos: carga de datos
- Explorar: explorar datos
- Análisis: analizar datos y realizar estimaciones
Análisis descriptivo de datos
1 Cargar librerías
Este paso ya lo realizamos y cargamos todas las librerías necesarias. Pero si, al trabajar los distintos script lo hacemos en sesiones diferentes, debemos volver a cargar las librerías.
En este práctico utilizaremos los siguientes paquetes:
pacman: este facilita y agiliza la lectura de los paquetes a utilizar en Rtidyverse: colección de paquetes, de la cual utilizaremos dplyr y havendplyr: nos permite seleccionar variables de un set de datospsych: para analizar descriptivamente datossjmisc: para analizar descriptivamente datoscrosstable: para tablas cruzadas o de contingencia
pacman::p_load(tidyverse, # colección de paquetes para manipulación de datos
dplyr, # para manipular datos
psych, # para analizar datos
sjmisc, # para analizar datos
crosstable) # para tablas de contingencia
options(scipen = 999) # para desactivar notacion cientifica
rm(list = ls()) # para limpiar el entorno de trabajo2 Importar datos
Usamos los datos creados en el procesamiento que se encuentran guardados en la carpeta output.
datos_proc <- readRDS("output/datos_proc.Rdata")3 Explorar datos
View(datos_proc) # Ver datos
names(datos_proc) # Nombre de columnas
dim(datos_proc) # Dimensiones
str(datos_proc) # Estructura de los datos (las clases y categorias de repuesta)En este caso, nuestra base de datos procesada tiene 496 casos y 9 variables.
4 Análisis
4.1 Estadísticos descriptivos para variables categóricas
Cuando tenemos variables catégoricas, sean nominales u ordinales, podemos utilizar tablas de frecuencias. Recordemos que las frecuencias es una manera ordenar datos según el valor alcanzado en la distribución de una variable.
4.1.1 Frecuencias
a) Absolutas y relativas
Para las variables nominales podemos usar tablas de frecuencias absolutas y relativas, y con ellas conocer la moda, es dedir, el valor con mayor cantidad de observaciones. Para ello, una manera sencilla de hacerlo es mediante la función table de R.
table(datos_proc$sexo)
Femenino Masculino
277 219 table(datos_proc$ingreso_minimo)
debajo minimo sobre minimo
211 285 table(datos_proc$autor_democ)
A la gente como uno, nos da lo mismo un regimen democratico que uno autoritario
112
En algunas circunstancias, un gobierno autoritario puede ser preferible a uno democratico
62
La democracia es preferible a cualquier otra forma de gobierno
287
Ninguna
35 Lo anterior nos entrega la frecuencia absoluta de las variables. Con ello, podemos observar que, en cuanto la preferencias entre autoritarismo y democracia, la mayoría de nuestros casos se concentran en “La democracia es preferible a cualquier otra forma de gobierno”. Para conocer la frecuencia relativa o porcentual de estas podemos utilizar el comando prop.table.
(freq_table1 <-table(datos_proc$autor_democ))
A la gente como uno, nos da lo mismo un regimen democratico que uno autoritario
112
En algunas circunstancias, un gobierno autoritario puede ser preferible a uno democratico
62
La democracia es preferible a cualquier otra forma de gobierno
287
Ninguna
35 prop.table(freq_table1)*100
A la gente como uno, nos da lo mismo un regimen democratico que uno autoritario
22.580645
En algunas circunstancias, un gobierno autoritario puede ser preferible a uno democratico
12.500000
La democracia es preferible a cualquier otra forma de gobierno
57.862903
Ninguna
7.056452 Así, podemos sostener que un 57,9% de los casos concideran que la democracia es preferible a cualquier otra forma de gobierno.
b) Acumuladas
Mientras que si trabajamos con variables ordinales, podemos usar también la frecuencia acumulada:
(freq_table2 <- table(datos_proc$tramo_ingreso))
Tramo 1 Tramo 2 Tramo 3 Tramo 4 Tramo 5
77 198 80 60 81 (freq_table3 <- prop.table(freq_table2)*100)
Tramo 1 Tramo 2 Tramo 3 Tramo 4 Tramo 5
15.52419 39.91935 16.12903 12.09677 16.33065 cumsum(freq_table3) Tramo 1 Tramo 2 Tramo 3 Tramo 4 Tramo 5
15.52419 55.44355 71.57258 83.66935 100.00000 A partir de este estadístico, podemos ver que un 55% de los casos se ubican debajo del tramo 2 de ingresos, lo cual en términos sustantivos señala que un 55% de las observaciones obtienen menos de $500.000 de ingresos mensuales.
También podemos unir todas estas frecuencias en una sola tabla:
tbl3 <- table(datos_proc$tramo_ingreso)
cbind(Freq=tbl3, relat = prop.table(tbl3)*100, Cum = cumsum(tbl3)) Freq relat Cum
Tramo 1 77 15.52419 77
Tramo 2 198 39.91935 275
Tramo 3 80 16.12903 355
Tramo 4 60 12.09677 415
Tramo 5 81 16.33065 496Otra manera de calcular frecuencias (absolutas, relativas y acumuladas) en R, es mediante la función frq() del paquete sjmisc, el cual entrega todo lo anterior con un solo comando.
sjmisc::frq(datos_proc$tramo_ingreso)x <character>
# total N=496 valid N=496 mean=2.74 sd=1.31
Value | N | Raw % | Valid % | Cum. %
----------------------------------------
Tramo 1 | 77 | 15.52 | 15.52 | 15.52
Tramo 2 | 198 | 39.92 | 39.92 | 55.44
Tramo 3 | 80 | 16.13 | 16.13 | 71.57
Tramo 4 | 60 | 12.10 | 12.10 | 83.67
Tramo 5 | 81 | 16.33 | 16.33 | 100.00
<NA> | 0 | 0.00 | <NA> | <NA>4.1.2 Tablas de contingencia
También podemos cruzar dos variables mediante las llamadas tablas de contingencia o tablas cruzadas. Además de conocer la frecuencia absoluta en cada casilla, podemos también conocer la proporción o frecuencia relativa para cada casilla y el total de la filas y columnas.
crosstable(datos_proc, cols = sexo, by = tramo_edad)# A tibble: 2 × 6
.id label variable Adultos `Adutos mayores` Jovenes
<chr> <chr> <chr> <chr> <chr> <chr>
1 sexo sexo Femenino 210 (75.81%) 44 (15.88%) 23 (8.30%)
2 sexo sexo Masculino 152 (69.41%) 49 (22.37%) 18 (8.22%)crosstable(datos_proc, cols = sexo, by = tramo_edad, total = "both") #fila y columna# A tibble: 3 × 7
.id label variable Adultos `Adutos mayores` Jovenes Total
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 sexo sexo Femenino 210 (75.81%) 44 (15.88%) 23 (8.30%) 277 (55.85%)
2 sexo sexo Masculino 152 (69.41%) 49 (22.37%) 18 (8.22%) 219 (44.15%)
3 sexo sexo Total 362 (72.98%) 93 (18.75%) 41 (8.27%) 496 (100.00%)crosstable(datos_proc, cols = sexo, by = tramo_edad, total = "row") #solo fila# A tibble: 2 × 7
.id label variable Adultos `Adutos mayores` Jovenes Total
<chr> <chr> <chr> <chr> <chr> <chr> <chr>
1 sexo sexo Femenino 210 (75.81%) 44 (15.88%) 23 (8.30%) 277 (55.85%)
2 sexo sexo Masculino 152 (69.41%) 49 (22.37%) 18 (8.22%) 219 (44.15%)crosstable(datos_proc, cols = sexo, by = tramo_edad, total = "column") #solo columna# A tibble: 3 × 6
.id label variable Adultos `Adutos mayores` Jovenes
<chr> <chr> <chr> <chr> <chr> <chr>
1 sexo sexo Femenino 210 (75.81%) 44 (15.88%) 23 (8.30%)
2 sexo sexo Masculino 152 (69.41%) 49 (22.37%) 18 (8.22%)
3 sexo sexo Total 362 (72.98%) 93 (18.75%) 41 (8.27%)4.2 Estadísticos descriptivos para variables númericas
A diferencia de las variables categóricas, a las variables numéricas (intervalaras o de razón) les podemos calcular una mayor cantidad de estadísticos descriptivos, como medidas de tendencia central, dispersión o posición.
Como ya vimos en clases:
- dentro de las medidas de tendencia central que podemos calcular para describir a una variable numérica encontramos: media, mediana;
- dentro de las medidas de dispersión podemos señalar: desviación estándar, variancia, coeficiente de variación, rango;
- dentro de las medidas de posición podemos mencionar: mediana, q1, q3, mínimo, máximo.
Tip
Recordemos que:
las medidads de tendencia central expresan el valor alrededor del cual se sitúa la mayor cantidad de los datos. Estamos mirando hacia el centro de los datos.
las medidas de dispersión buscan cuantificar lo próximo o alejado que están los valores de una variable de un punto central. Estamos mirando la dispersión de los datos respecto a su centro.
las medidas de posición señalan en qué “lugar” de una distribución se encuentra un dato o un conjunto de datos en relación al resto.
En R existen distintas formas de cálcular este tipo de estadísticos descriptivos.
a) Con summary
Podemos obtener rapidamente un resumen de los datos con la funcion summary de R
summary(datos_proc$ingreso) Min. 1st Qu. Median Mean 3rd Qu. Max.
0 350000 500000 679514 800000 5000000 Con esto podemos ver que el promedio o media aritmética del ingreso individual de los entrevistados de nuestra base es de $679.514, mientras que la mediana es de 500.000 pesos.
Asimismo, observamos que el 25% de la parte inferior de nuestros datos obtiene igual o menos de $350.000, en tanto que el 25% superior de la distribución de los datos gana igual o más de 800.000 pesos.
Sin embargo, aunque es informativo, no nos entrega toda la información que quisieramos.
b) Con psych
psych::describe(datos_proc$ingreso,
quant = c(.25,.75),
IQR = T) vars n mean sd median trimmed mad min max range skew
1 1 496 679514.1 611376.9 500000 572434.7 296520 0 5000000 5000000 3.01
kurtosis se IQR Q0.25 Q0.75
1 13.42 27451.63 450000 350000 800000Usando la funcion describe del paquete psych podemos obtener mayor cantidad de estadísticos, además de especificarle otros adicionales.
Así, por ejemplo, ahora además de la media aritmética y la media, también tenemos la media recortada.
Pero lo más relevante es que nos aporta estadísticos de la dispersión de los datos, como la desviación estandár que nos indica que el grado de dispersión de mis datos respecto al promedio de ingresos es de $611.376. Con esto, podemos obtener también la varianza de los datos, que corresponde a la DS al cuadrado.
Además de eso, nos aporta el rango (el valor máximo menos el mínimo), y el recorrido interquartilico (Q3 - Q1) que nos indica el grado de dispersión del 50% de los datos.
Con esta información, podemos calcular los demás estadísticos que necesitamos “a mano”, es decir, computandolos directamente en R como una cálculadora.
c) Con summarise de dplyr
Otra manera de obtener todos los estadísticos que necesitamos es utilizando dplyr. Aquí, le especificamos lo que requerimos, pero debemos saber bien cómo calcular tales medidas:
datos_proc %>%
summarise(media = mean(ingreso),
mediana = median(ingreso),
q1 = quantile(ingreso, probs = .25),
q2 = quantile(ingreso, probs = .75),
rango = max(ingreso) - min(ingreso),
desviacion_estandar = sd(ingreso),
varianza = var(ingreso),
coef_variacion = sd(ingreso)/mean(ingreso))# A tibble: 1 × 8
media mediana q1 q2 rango desviacion_estandar varianza coef_…¹
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 679514. 500000 350000 800000 5000000 611377. 3.74e11 0.900
# … with abbreviated variable name ¹coef_variacionAhora, conocemos no solo los estádisticos anteriores, sino que también obtuvimos la varianza y el coeficiente de variación.
Resumen
Hoy aprendimos a procesar datos en R. En detalle, vimos:
Cómo establecer un flujo de trabajo de procesamiento y análisis de datos en R.
Realizar análisis descriptivos en R según el nivel de medición de las variables